

【汽车芯片】基于RL神经网络计算加速的自动泊车SoC架构
内容提要:我们设计了一个片上系统(SoC)架构,其中包含我们的ANN加速器和在ARM处理器上实现的主控制器。我们的硬件加速器专为ANN工作负载量身定制,并且可以以较低频率高效并发地执行必要的计算,以获得比基于处理器的解决方案更高的性能。这样可以最大限度地减少能源消耗并消除能源浪费。我们的系统在示例停车环境中自主完成停车任务。
摘要
现代世界中,完全自动驾驶汽车在改善道路安全、最大限度地减少交通拥堵、减少维护和保险成本以及使驾驶更加舒适等方面有很多好处。如今,人们已经进行了研究来解决自动驾驶汽车的一些特定任务,例如将汽车保持在车道上、控制速度、紧急制动或自动寻找停车场。在这项工作中,我们的主要目标是构建一款自动驾驶模型汽车,通过训练有素的神经网络(ANN)解决停车问题,这些神经网络在FPGA上加速以进行实时部署。设计并采用两种不同的基于深度强化学习(RL)且具有不同奖励机制的人工神经网络来解决自助停车问题。首先,神经网络负责处理传感器数据,然后在停车场安全地导航汽车。图像处理算法与第一个模型同步工作,通过处理摄像头捕获的图像来确定是否有适合的停车场。第二个模型执行停车过程。我们设计了一个片上系统(SoC)架构,其中包含我们的ANN加速器和在ARM处理器上实现的主控制器。我们的硬件加速器专为ANN工作负载量身定制,并且可以以较低频率高效并发地执行必要的计算,以获得比基于处理器的解决方案更高的性能。这样可以最大限度地减少能源消耗并消除能源浪费。我们的系统在示例停车环境中自主完成停车任务。
1.简介
人工智能(AI)是一个关键研究领域,有可能解决当今世界中没有可行解决方案的许多不同问题。过去十年来,汽车行业一直专注于人工智能在自动驾驶汽车中的应用。自动驾驶汽车将有助于改善道路安全,最大限度地减少交通拥堵,减少维护和保险成本,减少燃料消耗,减少温室气体排放,并使驾驶更加舒适。全自动驾驶汽车仍然无法面世,而且还需要数年时间。
神经网络是计算密集型的,可用于从高性能自动驾驶汽车到低功耗边缘设备的许多不同领域。我们本研究的目标是使用人工神经网络解决自动停车问题。如果需要高性能和高功效,那么在传统的基于冯诺依曼式处理器的嵌入式系统中实现ANN是一个糟糕的选择。人工神经网络的高效硬件实现在这些应用中发挥着关键作用,但它们有其自身的硬件限制:大量片上存储器需求、低功耗和高速处理能力以及设计灵活性。
随着自主系统和IoT(物联网)设备的使用越来越多,嵌入式系统技术已成为热门研究领域。功耗和高速处理能力是设计嵌入式智能物联网系统时需要考虑的重要指标,该系统由用于实现自主的ANN组成。降低功耗是嵌入式系统中最重要的挑战之一。特别是,为了在自主系统中成功实施人工神经网络,需要高性能和节能的解决方案。由于GPU的多核结构,可以通过对多个数据的并行计算获得高处理速度。然而,已经展示了基于FPGA的ANN硬件架构,在能耗和性能方面,它们的效率比基于GPU的解决方案高10倍。为复杂和计算密集型工作负载设计硬件架构(例如使用低级硬件描述语言、VHDL或Verilog在FPGA上实现的ANN)在时间和精力方面效率低下。本文旨在使用高级综合工具来提高设计效率,并提出一种使用硬件/软件协同设计方法的片上系统(SoC)架构。
本文的主要目的是通过特殊的硬件设计获得节能和高工艺性能,确保原型模型车能够在公园环境的空停车场中自主停车。模型车将首先在停车场周围漫游时检测停车场,然后使用两个基于深度Q学习的不同神经网络(具有不同的奖励机制)执行停车过程。第一个神经网络负责利用传感器数据在停车场安全地导航汽车。图像处理算法与第一个模型同步工作,通过处理摄像头捕获的图像来确定是否有空的停车场。第二个神经网络执行停车过程。他们都在仿真环境中接受训练,该环境非常接近我们的模型车实现的物理停车环境。我们为这些ANN设计了特殊的硬件,这将加速这些ANN在FPGA上所需的计算,以便以足够快的速度和高能效产生输出,这是基于处理器实现无法实现的。
A.相关工作
强化学习方法在自动驾驶汽车中得到了相当频繁的使用。Raspberry Pi等单板计算机通常用于自动驾驶汽车原型研究。即使这种方法足以确定人工智能在真实环境中的行为,但仍需要实现更节能的结果才能将其应用到真实车辆中。特定应用的硬件设计在许多领域提供了巨大的优势,不仅在自动驾驶汽车中,而且特别是在基于卷积神经网络(CNN)的深度学习算法中。此外,一种用于反向传播算法的RTL级专用硬件加速器,用于训练全连接(FC)ANN,并且这种基于FPGA的实现优于其他多核C和Matlab实现。FC-ANN可以构成CNN或 ANN的最后一层,并且在当前的神经网络模型中大量使用。还有其他工作可以通过减少FC网络中的连接数量和设计特殊的VLSI实现来降低内存需求并节省能源来提高FC DNN的计算效率。
旨在通过降低车辆停车过程中的事故率来提高驾驶的可靠性和自动驾驶汽车的普及率,并以实用、节能和高的过程性能实现这一过程。
B.贡献
本研究的主要贡献如下:
•通过使用ANN算法的HLS指令,在能耗和计算性能方面创建高效的硬件设计,
•使用深度Q学习提出仿真环境中停车问题的解决方案,
•创建必要的软件/硬件设计并在原型车上测试人工神经网络加速器。
2.问题分析
本研究主要有2个步骤。第一步是通过深度Q学习解决停车问题。第二步是通过高级综合为ANN创建高效的硬件架构,并将其集成到SoC架构中。
A.采用深度Q学习的自动停车
强化学习是训练机器学习模型以做出一系列决策。深度Q学习是一种无模型强化学习算法,用于学习告诉智能体在什么情况下采取什么行动的策略。这项研究重点关注当今非常流行的自动驾驶和自动停车。许多汽车公司正在努力增强其车辆的自动驾驶功能。汽车公司未实现的停车过程中适当的停车场检测步骤也被建模为自动驾驶。在大城市的交通中会造成时间损失并增加压力率。由于人无法像机器那样做出精确和准确的决策,不断自我改进的人工智能算法可以使驾驶变得更加经济。结果表明,经过深度Q学习训练的ANN成功完成了停车任务。其中一个ANN模型允许车辆安全移动直到找到合适的停车场,另一个模型完成停车过程。
B.设计硬件加速器
基于人工智能的应用经常使用Python-Keras等高级语言的库来实现。然而,这些可以编译成嵌入式系统中传统冯诺依曼式处理器的库在能耗和处理性能方面存在不足。特别是在自动驾驶汽车中,人工神经网络必须产生快速输出以提高安全性。在产生足够快的输出的同时提供低能耗对于电池寿命而言非常重要。能够同时满足这两个要求的唯一解决方案是为此工作负载设计特定于应用程序的硬件设计。可以创建在低频运行时产生快速输出的硬件设计。特殊的硬件设计由于其低频运行可以节省能源。ANN是计算复杂的算法。算法3显示了两个隐藏层之间的计算阶段。通过VHDL、Verilog等底层硬件设计语言生成该算法的硬件加速器是一个困难的过程。在本研究中,使用了HLS,它可以从高级C代码生成硬件设计。表2总结了本研究中获得的加速,表3列出了资源利用率。从表中可以看出效率,与ARM处理器相比,实现了17倍的加速,
C.软硬件协同设计
硬件/软件协同设计研究复杂电子系统的硬件和软件组件的并行设计。它利用硬件和软件的协同作用,旨在优化和/或满足最终产品的成本、性能和功率等设计约束。与此同时,它的目标是大幅缩短上市时间。在这项工作中,软件和硬件上的组件应该单独但同步地工作。软件硬件协同设计旨在使软件和硬件组件能够在SoC上协同工作。AXI通信用于组件的同步操作。使用Zynq ARM处理器控制组件,并在Zynq ARM上执行软件友好的操作。在硬件设计上运行能够从传感器和摄像头以及ANN加速器接收数据的设计。使用Zynq ARM处理器完成了将传感器值作为输入发送到加速器、加速器之间的同步、通过管理硬件设计来控制电机等过程。
3.方法
该方法由4个主要部分和子部分组成。
A.神经网络模型的训练
此阶段包括使用深度Q学习对ANN进行训练。训练好的模型被保存以用于硬件设计。
1)仿真:应用深度Q学习方法需要进行仿真。代理应该通过实验来解决问题,这个阶段可能需要很长时间。在真实环境中从头开始训练人工神经网络几乎是不可能的。为了使在仿真环境中训练的ANN能够在真实环境中获得相同的结果,仿真必须与现实世界的物理现象兼容并且可扩展。考虑到这种情况,仿真环境完全由团队使用基于Python的pygame模块设计,车辆的运动能力和缩放比例可以轻松调整为真实原型。图1展示了团队创建的仿真环境和真实环境。(参考资料1,关注牛喀网公众号,后台咨询下载)

图1:仿真和真实环境
2)深度Q学习算法:深度Q学习有以下2个主要对象:试图解决问题的代理,可以应用所选动作的环境。这两个主要对象之间的关系如图2所示。Q学习过程为工作代理创造了一种知识,它可以参考这些知识来最大化其长期回报。Q学习过程中的知识积累存储在表格中,但在这种方法中,车辆必须事先尝试过所有可能的情况。在深度Q学习中,人工神经网络用于构建知识,并且当智能体与环境交互时,人工神经网络会进行更新。这种人工神经网络可以为任何状态做出正确的决策,即使以前没有尝试过。因此,在此类应用中使用人工神经网络非常重要。基于Python的Keras模块用于深度Q学习算法中使用的ANN。Keras模块非常有用,因为它具有与ANN的高级接口。Q学习技术的应用与算法1相同。深度Q学习算法中使用的贝尔曼方程如方程1所示。贝尔曼方程确保在代理训练期间考虑下一步行动。
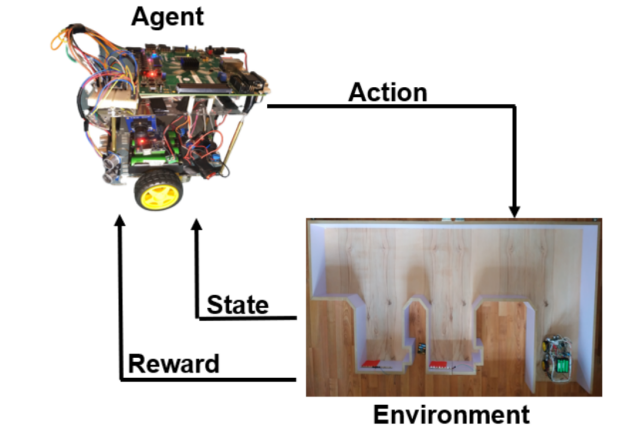
图2:Q学习时间表

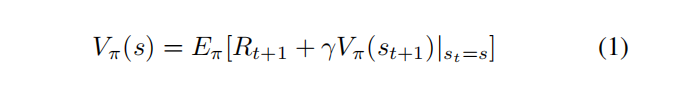
在训练过程中,开发了评分系统来观察模型的学习情况。代理在每一个动作中都增加了他的分数,这并没有错。已通过分数限制的智能体的ANN模型已被保存。手动检查已保存模型的行为(任何状态的操作)。表1给出了工作中使用的模型。由于停车任务比在停车区域无碰撞移动更复杂,因此用于停车的神经网络有更多的神经元。
深度Q学习方法最复杂的方面之一是创建奖励机制。为2个深度Q网络创建了不同的奖励机制。以下奖励机制为在停车区执行搜索任务的ANN提供了成功的结果。人们研究如何保持机制尽可能连续并将奖励保持在一定规模内。实验中成功的奖励机制之一的算法如算法2所示。某些情况,例如“parking_completed”、“getting_close_to_park”仅对提供停车任务的代理有效。

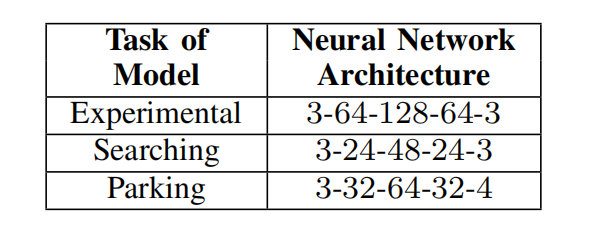
表1:神经网络模型
B.为预训练模型设计硬件加速器
人工神经网络是计算密集型运算,因为它们需要大量的浮点乘法和求和。特定于应用的硬件设计可以提供具有高处理能力的节能解决方案,因为与GPU相比,它允许更多地增加所需的并行处理,并且可以应用特定于应用的流水线方法。本研究中使用的特定于ANN的加速器设计包括以下两个阶段。
1)实现神经网络的纯C代码:由于硬件设计使用高级综合器,因此为每个模型创建了神经网络架构的C代码。算法3显示了两个隐藏层之间的计算阶段。对于下一层的每个神经元,上一层的所有神经元都乘以不同的权重,然后将结果相加。由于使用修正线性单元(ReLU)作为激活函数,如果总结果为负,则将“0”值转移到下一层,如果总结果为正,则将结果直接转移到下一层 。
2)通过HLS创建硬件设计:在本研究中,基本上使用了2种优化方法。第一个优化是对提供内存单元访问的端口不足的安排。有必要在这些序列中创建足够数量的内存端口,以便并行执行操作,同时达到序列上的权重和神经元值。这些数组通过使用ARRAY_RESHAPE pragma重新排列,以免处理单元等待。我们使用的第二种方法是PIPELINE pragma,它确保一个周期中迭代之间的时间可以在最里面的周期中以1个周期时间结束。此过程提高了资源利用率并大幅提高了速度。


C.SoC(片上系统)架构
SoC本质上是一种集成电路,它采用单一平台并将整个电子或计算机系统集成到其上。SoC包括硬件和软件。其组件通常包括可能是多核的中央处理单元(CPU)、FPGA和系统存储器(RAM)。AXI(高级可扩展接口)协议如今被许多SoC设计人员使用,并且是AMBA(Arm高级微控制器总线架构)规范的一部分。它在Xilinx的Zynq器件中尤其流行,提供处理系统和芯片的可编程逻辑部分之间的接口。该协议只是设置芯片上不同模块如何相互通信的规则,在所有传输之前需要类似握手的过程。软件开发套件(SDK)是我们可以对Zynq ARM处理器进行编程的平台。SDK通过允许我们对Zynq ARM处理器进行编程来控制和同步硬件设计。此外,在arm处理器上进行软件友好的操作。处理器和硬件设计之间的通信通过AXI接口实现。
本工作对系统的各个部分进行了单独的模块设计,这些设计如下:
1)神经网络架构设计:本研究的贡献之一是提出了一种方法,通过高级编程语言抽象,使用高级综合,以更简单、更具成本效益的方式,加速自动泊车的神经网络计算。对于系统中使用的每个神经网络,都设计了一个神经网络加速器,并将其集成到汽车的SoC中。这些设计基本上用于使用来自传感器的数据来决定车辆的下一步移动。
2)相机接口IP核设计:OV7670相机模块用于从环境中读取像素数据。需要硬件IP(知识产权)核心来从低级相机接口捕获数据。负责从相机捕获帧的IP核有3个基本块。这些块:捕获、控制器和处理。控制器负责相机的设置,捕获模块负责管理像素输入和处理。块提供ARM处理器和捕获模块之间的通信。
3)HCSR-04块设计:创建一个自定义IP,基本上是可重用的硬件块设计,用于使用原型中使用的距离传感器信息来测量距离。该IP具有输出“触发”信号和输入“回声”信号。为了实现模型车的有效停车系统,系统上安装了3个距离传感器。由于原型有3个距离传感器,因此在块设计中添加了3个hcsr_04_ip。算法5指的是HCSR-04距离传感器的VHDL级距离测量。捕获触发脉冲信号和生成回波信号的所有必要计算都是在硬件上完成的,以便测量距离。触发输出信号被置为高电平至少10μs。由于Zynq SoC芯片的PL部分运行在100MHz,计数器计数到1000,以便测量10us,如算法5所示。因此,在10us期间向触发器提供高信号。当回波信号返回时,它会生成一个脉冲信号,脉冲宽度与传感器和旁边物体之间的距离成正比。算法5中看到的数字5882对应于计数器操作的声波行进1厘米在100MHz。
4)电机控制块设计:创建定制IP核来控制模型车轮。该IP有输出“右”和“左”。使用Arduino将ZedBoard相应的动作输出传输给直流电机。

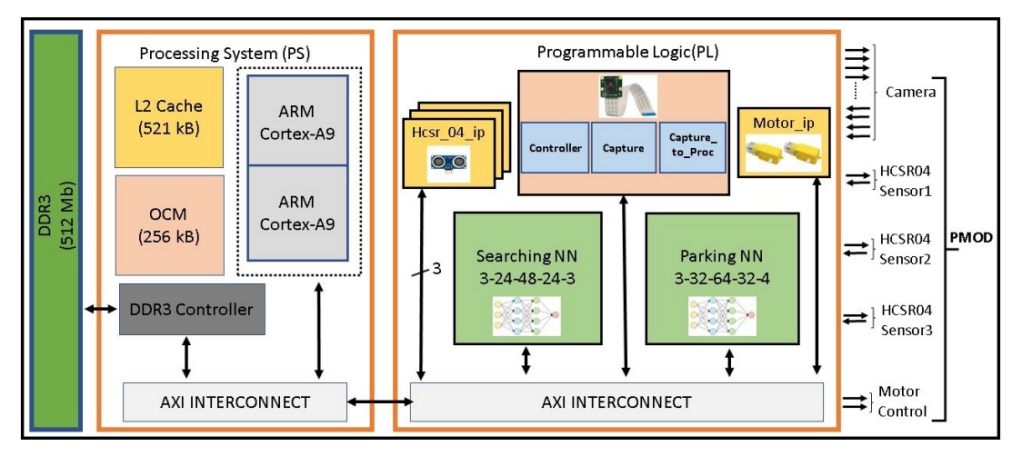
图3:片上系统(SoC)架构的模块设计
4.实验工作
A.实验设置
在本研究中,使用PythonPygame模块创建仿真来实现深度Q学习方法。仿真环境的缩放是在考虑原型尺寸的情况下完成的。同样,车辆在仿真环境中的运动能力也是根据原型设计的。使用经过训练的权重创建的C代码将在Linux操作系统中使用GNU编译器进行测试。将使用Vivado HLS 2017.4创建经过验证的C代码和设计IP的硬件设计。SoC架构将使用Vivado Design Suite 2017.4创建。Zynq处理器和使用HLS创建的硬件加速器将包含在该架构中。创建的SoC架构将在ZedBoard Zynq-7000卡上实现,并在输出验证后在原型上进行测试。创建了Hcsr-04传感器IP和电机控制IP,并在原型上进行了测试。将距离传感器和Arduino连接到ZedBoard时使用TXS0108E 8通道逻辑电平转换器。因为ZedBoard的引脚提供3.3V,而Arduino和距离传感器使用5V。Arduino设置为根据Zedboard 2个引脚的数据来移动电机。
B.实验结果
表2分别列出了每个神经网络在ARM处理器和硬件加速器上的软件实现的执行时间。该硬件设计的运行频率(100MHz)比ARM处理器(667MHz)低得多,但输出速度却快了大约17倍。为了实现节能设计,在低频下达到这个速度非常重要。为了创建另一个视角,我们在执行模型验证的Python-Keras模块上测量了模型的执行时间。该模型在Python-Keras(具有2.6GHz 4核8线程处理器的Intel i7-6700HQ)上以10.4 µs生成输出。这表明,与Keras模块相比,它实现了更高的处理性能,而Keras模块是在硬硅处理器上工作的高度优化模块。根据第一个实验(Experimantel模型)的加速和资源使用情况,决定了研究中使用的原始模型的规模。第一个实验中使用的指令用于FC模型2和3。该模型(搜索模型)将提供对车辆的控制,直到找到停车区域,已达到足够的加速度,如表1所示。除了硬件设计之外搜索模型在资源利用方面非常合适,如表2所示。执行停车过程的模型(停车模型)比搜索模型包含更多的神经元。预计它会比搜索模型使用更多的资源来达到相同的加速率。然而,设计不需要额外的优化,因为它使用了可接受的资源量。检查模型产生的输出并验证合成过程已成功完成。由于捕获的像素数据不存储在存储器中,因此为相机创建的设计的资源使用不会对其他设计产生限制影响。通过读取摄像头数据来测试红色物体检测并进行验证。
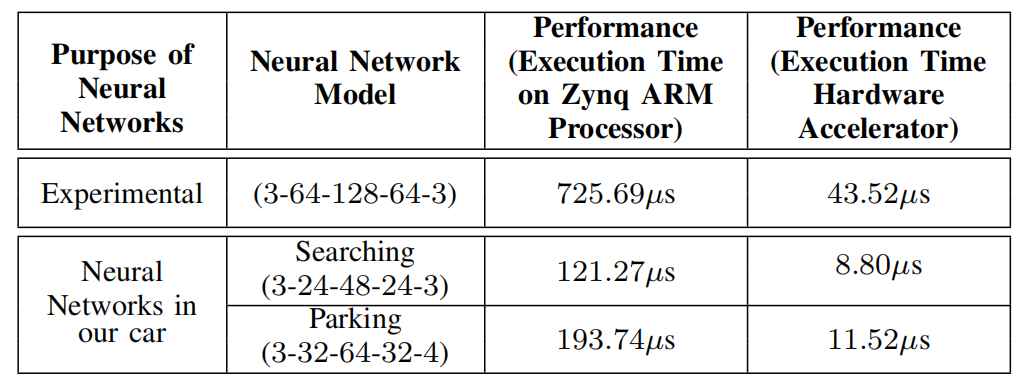
表2:模型的执行时间
如表3所示,为电机控制HCSR-04传感器创建的硬件设计的资源使用量非常低。因为这些值是通过单个寄存器获取的。使用单个寄存器读取HCSR-04传感器IP中测量距离值的个位和十位。同样,在电机控制IP中使用单个寄存器来控制左右移动。如果传感器是基于软件的,则将按顺序读取距离值,因此这会导致延迟。在我们的工作中,所有三个传感器都可以同时测量。除此之外,传感器在测量距离的同时,摄像头也可以同时收集数据。所有这些会导致软件延迟的过程都被转移到可编程逻辑中,并利用表3所示的资源获得了高效的硬件设计。当我们查看资源使用情况时,ANN加速器使用了LUT总面积的63%。人工神经网络加速器可以设计为在拥有更多资源的系统上产生更快的输出。
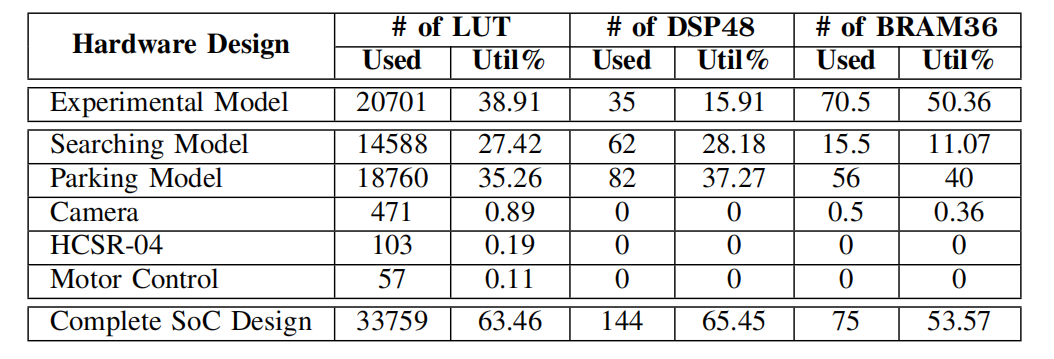
表3:硬件设计的资源利用
5.结论
在这项工作中,基于RL的ANN的硬件加速器是使用高级综合工具设计和实现的。底层硬件设计抽象提供了完全定制的硬件设计,但设计复杂性和成本很高。结果表明,与底层硬件描述语言的设计效率较低相比,高级设计抽象的自动停车工作负载可以获得低频、更快和节能的结果。我们提出的基于Vivado HLS的硬件架构,即使在可编程硬件上以比ARM处理器(667MHz)低得多的频率(100MHz)运行,速度也快了17倍。表2给出了允许模型车辆导航并进入停车场的模型的硬件设计的资源利用率。据观察,当ANN模型变大时,优化的硬件设计中BRAM的使用呈指数级增长。基于此,停车问题的解决无需使用包含神经元数量的非常大的模型。对于大型ANN模型,如果通过VHDL和Verilog等低级语言手动设计硬件,设计复杂性会增加。这项研究展示了更高抽象层的特定应用硬件设计的速度和节能优势。据观察,高级综合使设计阶段变得更加容易。基于深度Q学习的自动泊车已在模型车及其环境的SoC架构上成功完成。

详询“牛小喀”微信:NewCarRen

详询“牛小喀”微信:NewCarRen
作者:牛喀网专栏作者
牛喀网文章,未经授权不得转载!
相关文章



